I have a big pile of notes. Years of them, mostly in Obsidian, and a good chunk are Rust learning notes I keep going back to. The problem with a big pile of notes is that searching them is keyword search, and half the time I don't remember the keyword, I remember the idea. So this I built a tiny RAG app that lets me just ask my notes a question in plain English and get an answer back, with citations pointing at the exact files the answer came from.
I called it wiki-rag. It's a small FastAPI service: you point it at a folder of notes, it reads them, and then you can ask it things. Right now I have it pointed at my Rust notes, but it'll happily eat any folder of markdown (or PDFs, or HTML, whatever).
So even though I built it to talk to my own notes, the same thing works for a lot of other piles of text. Product docs or an internal wiki or API references, where you just want a quick answer instead of going through pages. A general knowledge base for a team or an org. A folder of research papers. A customer support pipeline answering from your help docs. Honestly any pile of notes where the answer is in there somewhere and you'd rather just ask than go hunting.
I write up most of the things I build, partly because teaching forces me to actually understand what I made, and also because I want to remember the decisions later. So this is that writeup. It's a bit of a build log.
What it actually does
There's a web UI (a textarea, answers rendered as markdown, a ChatGPT-style sidebar of past chats):
Under the hood the whole thing is one API call:
POST /query { "question": "what are the three rules of ownership in rust?" }
{
"answer": "1. Each value has a variable called its owner. 2. There can
only be one owner at a time. 3. When the owner goes out of
scope, the value is dropped [rust 8 - ownership OBRM.md].",
"sources": ["rust 8 - ownership OBRM.md", "rust 9 - ownership.md"]
}
That [rust 8 - ownership OBRM.md] in the answer is the bit I care about most. RAG only earns trust if it tells you where it got the answer, so the model is instructed to cite the filename inline, and the sources array lists every file the retrieved chunks came from.
The stack
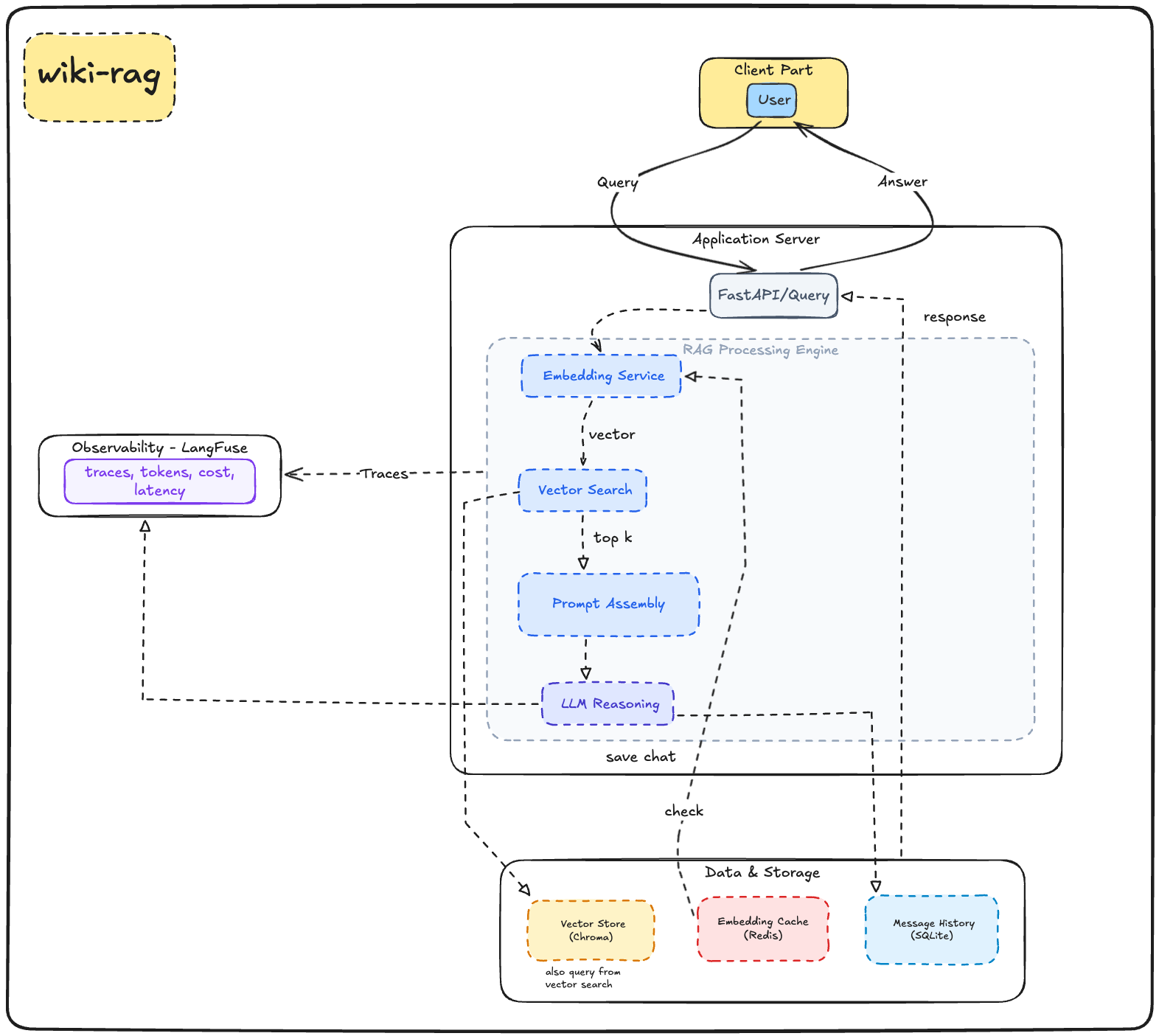
Python 3.13 (via uv), FastAPI + Pydantic v2, LangChain 1.x, Chroma as the vector store (just a local file), Redis 7 for caching embeddings, SQLite (stdlib) for the chat history, OpenAI gpt-4o-mini for the answers and text-embedding-3-small for the embeddings, LangFuse for observability, and Ragas for the eval harness. Type-checked with basedpyright, linted with Ruff.
That looks like a lot but most of it is one import and a couple of lines. The framework does the heavy lifting. The interesting part was never the amount of code, it was the decisions.
How it works
There are two halves: ingest once, then answer forever.
Ingest (run it once, re-run when the notes change):
- Walk the folder, read each file
- Split into ~1000-character chunks
- Ask OpenAI to embed each chunk (cached in Redis so re-runs skip the API)
- Write everything to a local Chroma file, keeping each chunk's file path as metadata
That file path is the whole trick behind citations later.
Answer (every question):
- Embed the question
- Ask Chroma for the 4 closest chunks by vector similarity
- Build a prompt: those chunks, the question, and "cite filenames inline"
- Send it to
gpt-4o-mini - Return the answer plus the list of filenames the chunks came from
That's it. That's RAG. Look up the relevant bits, then answer from them.
Building it, and the things I almost got wrong
I built this in stages, and honestly the most useful parts to write down are the small things I got wrong on the first pass.
Config: .env is the only place that knows things
My first config.py duplicated values as defaults:
langfuse_base_url: str = "https://jp.cloud.langfuse.com"
redis_url: str = "redis://localhost:6379"That's wrong, and I caught it pretty much immediately. If a value lives in .env, the Settings class should declare its type and nothing else. A default in code just duplicates the value, and then the two drift apart and you can't tell which one is real. So the final shape declares types only:
class Settings(BaseSettings):
model_config = SettingsConfigDict(env_file=".env", extra="ignore")
openai_api_key: SecretStr
langfuse_public_key: str
langfuse_secret_key: str
langfuse_base_url: str
redis_url: str
vault_corpus_path: Path
chunk_size: int = 1000
chunk_overlap: int = 200The two defaults that stayed (chunk_size, chunk_overlap) are tuning knobs with a universally fine fallback. An environment-specific URL is not that.
Capping the input before it costs me money
The /query endpoint takes a string. Pydantic will happily accept a 10MB string by default, and a 10MB string quietly becomes a 10MB embedding call and a 10MB prompt. So the very first thing on the request model is a bound:
class QueryRequest(BaseModel):
question: str = Field(min_length=1, max_length=2000)Costs nothing to add now, very annoying to remember after the surprise bill.
LangChain 1.x moved everything
LangChain went through a big reorg for 1.x, so basically every tutorial answer imports from a path that no longer exists. I kept seeing this warniong so I felt like, this is something I definitely need to fix, so I stopped trying to read migration docs and just wrote a tiny probe to find where things actually live:
import importlib
for path in [
'langchain.embeddings.CacheBackedEmbeddings',
'langchain_classic.embeddings.CacheBackedEmbeddings',
]:
mod, _, name = path.rpartition('.')
m = importlib.import_module(mod)
print('OK ' if hasattr(m, name) else 'NO ', path)For the record, in 1.x: CacheBackedEmbeddings is in langchain_classic.embeddings, the loaders and Chroma and RedisStore are in langchain_community.* (which works but warns that it's being sunset), RecursiveCharacterTextSplitter is its own langchain_text_splitters package, and OpenAIEmbeddings / ChatOpenAI are in langchain_openai.
The Redis cache was the fun part
Embeddings actually cost money and they're deterministic. The same chunk of text always embeds to the same vector. That's the shape for a cache. CacheBackedEmbeddings wraps the OpenAI embedder so that before each call it hashes the text, checks Redis, and only calls OpenAI on a miss:
underlying = OpenAIEmbeddings(model="text-embedding-3-small",
api_key=settings.openai_api_key)
store = RedisStore(redis_url=settings.redis_url, namespace="wiki-rag")
embeddings = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings=underlying,
document_embedding_cache=store,
namespace=underlying.model,
)The numbers on my Rust notes (17 files, 92 chunks):
| Run | Wall time | OpenAI calls |
|---|---|---|
| Cold (empty Redis) | ~15s | 92 |
| Warm (cache full) | ~1s | 0 |
About 17x faster on the second run, for $0. And it generalises: any pure, expensive, content-addressable function (embeddings, completions, scrapes) wants exactly this wrapper.
Chroma keeps adding, so re-ingest doubles everything
Chroma.from_documents always adds the new chunks on top of whatever is already there. The first time I re-ran ingest I would have silently ended up with two copies of every chunk. The fix is to wipe and rebuild:
if CHROMA_DIR.exists():
shutil.rmtree(CHROMA_DIR)
_ = Chroma.from_documents(documents=chunks, embedding=embeddings, ...)Destructive on purpose. You re-ingest because the notes changed, so you want the new state, not the union of old and new.
Build the clients once, not per request
My first rag.py built the vector store and the LLM client inside the request handler, so every single /query re-opened the Chroma file and set up a new HTTP client. I noticed because the requests felt slower than they had any right to be. The one-line fix is process-lifetime singletons:
@lru_cache(maxsize=1)
def _vectorstore() -> Chroma: ...
@lru_cache(maxsize=1)
def _llm() -> ChatOpenAI: ...First call builds, every call after returns the cached instance. It's the no-ceremony version of "set this up once at startup."
Async all the way down
FastAPI's whole point is handling lots of requests on one event loop. If your handler is async def but you call a synchronous network method inside it, you've blocked the loop and thrown away the concurrency. LangChain has async variants of every I/O method, prefixed with a:
docs = await _vectorstore().asimilarity_search(question, k=k)
response = await chain.ainvoke({"context": ..., "question": question})The annoying thing is that similarity_search (no a) also works, it just quietly blocks. My code-review habit now is to grep any async handler for .invoke( or .search( without the a.
The four-line prompt that fixed citations
SYSTEM_PROMPT = (
"You are a precise assistant answering questions about Rust based only on "
"the provided context. If the context does not contain the answer, say so "
"plainly. Cite source filenames inline like [filename.md]."
)Three jobs in there. "Based only on the provided context" narrows the model down. "If the context does not contain the answer, say so plainly" is the explicit permission to admit it doesn't know, and without that line the model will absolutely make something up to fill the gap. And "cite filenames inline like [filename.md]" pins the citation format, because an earlier draft just said "cite your source" and the model picked a different format every single call, which would have made the eval harness miserable later.
My RAG quoted my diary
The first working version answered the ownership question correctly but listed 2026-03-31.md as a source. That's a daily journal entry that happens to mention Rust, and my directory loader's glob was **/*.md, which recursively grabbed everything including my journal folder. Not wrong exactly, but journal entries are stream-of-consciousness, not authoritative answers, and they were going to cost me faithfulness points. The fix was boring: tighten the glob from **/*.md to *.md so it only reads the top-level notes.
Observability before optimization
I wired up LangFuse before I tuned anything, because I wanted to see token counts and cost per call before guessing at improvements. LangFuse rebuilt its integration on top of OpenTelemetry, so the import every tutorial shows you (from langfuse.callback import CallbackHandler) doesn't exist anymore. The real wiring is small:
from langfuse import Langfuse
from langfuse.langchain import CallbackHandler
response = await chain.ainvoke(
{"context": ..., "question": question},
config={"callbacks": [_langfuse_handler()]},
)One config kwarg and every /query shows up as a trace with tokens, latency, and cost in USD.
The eval harness, and the Ragas mess
The thing I actually wanted out of this project was an eval harness, so I could change retrieval and know whether I made it better or worse instead of just vibing. I wrote 5 golden questions over the Rust notes and scored them with Ragas on two metrics, Faithfulness (is the answer grounded in the retrieved context) and Answer Relevancy (does it actually answer the question). Real numbers, run twice:
| Metric | Run 1 | Run 2 |
|---|---|---|
| Faithfulness | 0.946 | 1.000 |
| Answer Relevancy | 0.902 | 0.900 |
Faithfulness wobbles between runs because Ragas uses an LLM to grade it. Answer Relevancy is steadier because it's embedding-based.
Getting Ragas to run at all was a fight, though. Version 0.4.3 is mid-migration and importing it just crashed:
ModuleNotFoundError: No module named 'langchain_community.chat_models.vertexai'
Ragas imports a module that langchain-community deleted a couple versions back. So I had to write a sys.modules shim that registers a stub for the missing module before Ragas gets a chance to import it:
import sys, types
_stub = types.ModuleType("langchain_community.chat_models.vertexai")
class _ChatVertexAIStub: pass
setattr(_stub, "ChatVertexAI", _ChatVertexAIStub)
sys.modules["langchain_community.chat_models.vertexai"] = _stubThen eval.py imports that shim as its literal first line. There was a second round of pain where Ragas exposes two metric APIs (a legacy one and a new "collections" one) and the new one isn't actually wired into evaluate() yet, so I went back to the legacy path and moved on. Sometimes the move is to stop fighting the new API and use the deprecated one that works.
From 30 type errors to 0
I'd been ignoring red squiggles in my editor for a while, assuming they were stub noise. Then I ran the type checker from the terminal:
uvx basedpyright src/wiki_rag/
30 errors, 39 warnings, 0 notesTurns out some were real. I was passing a plain str as the OpenAI API key where it wanted a SecretStr. It worked at runtime because Pydantic coerces it, but the type was genuinely wrong. The fix was one line at the source: declare openai_api_key: SecretStr in Settings, and all three call sites started type-checking correctly (LangChain accepts SecretStr natively, no .get_secret_value() boilerplate). One annotation, three bugs gone.
Most of the rest (~35) was LangChain's incomplete type stubs, which I silenced project-wide in pyproject.toml rather than littering ignore comments everywhere. And one dumb one I want to flag because it'll get you too: # type: ignore[call-arg] is mypy syntax and basedpyright silently ignores it. basedpyright wants # pyright: ignore[reportCallIssue]. With the wrong tag the comment does nothing and you don't find out until you run the checker and go "wait, that was supposed to be suppressed."
The lesson I keep relearning: run the linter from the terminal, not just the editor. A count in your face is harder to ignore than a tooltip.
A useful 503
There's one obvious foot-gun: start the server before you've run ingest, ask a question, and the old behaviour was a cryptic Chroma error. So I made it an actionable one:
class VectorStoreNotInitializedError(RuntimeError):
"""Raised when chroma_db/ is missing; run ingest first."""main.py catches it and returns 503: vector store not found... run python -m wiki_rag.ingest first. The user gets told exactly what to do.
What it's not for
RAG breaks the moment the question doesn't fit "look up a few chunks, then answer." The big failure mode is asking about something that isn't in the folder, where the model either says "I don't know" (the prompt tells it to, and usually it listens) or confidently invents something. A bigger model does not fix this. The fix is always adding the right document, not buying a smarter LLM.
It's also wrong for anything that needs reasoning across all your data instead of a few chunks. "Compare these 50 companies and rank them" is a database query, not a RAG one, because RAG only ever hands the model a handful of chunks and it never sees enough to compute the answer.
And ingest is a snapshot, so if I edit my notes I have to re-ingest before the new stuff is searchable. That re-ingest is cheap, though, because of the Redis embedding cache: only new or changed chunks hit OpenAI.
What's missing for prod
This is a personal tool, so I deliberately skipped a bunch of things I'd need for anything real: auth on /query, rate limiting, swapping the local Chroma file for pgvector or a managed store, and streaming the response so the UI fills in token by token instead of waiting for the whole answer. All known, all out of scope for this project.
Closing
The thing I keep coming back to is how little code this actually was. The whole RAG core is maybe 60 lines of Python, because LangChain and Chroma and Redis are each one import and a couple of calls. The work wasn't writing code, it was the decisions: where config lives, capping the input, caching the embeddings, pinning the citation format, cleaning up the notes, and writing an eval so I can tell whether a change helped. That's the part worth keeping.
The code is on GitHub if you want to point it at your own pile of notes.